erDiagram
direction LR
plants }o--|| sampling_events : "sampled in"
plants {
int sampling_event_id FK
string site_name
int plot_num
int individual_num
float crown_wid_cm
float plant_ht_cm
}
sampling_events }|--|{ plots : samples
sampling_events {
int sampling_event_id PK
int site_id FK
dateTime sample_date
string observer
}
plots {
int plot_id PK
string site_name
int plot_num
float centroid_lat
float centroid_long
string treatment
}
Collect, manage and describe research data
Overview
🚧 Most of this chapter is under construction.
In this chapter we present important considerations and best practices for collecting quality Jornada data that can be used in the future. The guidance here varies depending on the data being collected — there are many kinds of research data — but some common themes apply. Try to use consistent, community-supported standards to collect, format, and clean your data, all while describing the process and data products with rich metadata. Following these recommendations will get your research data workflow off to a good start.
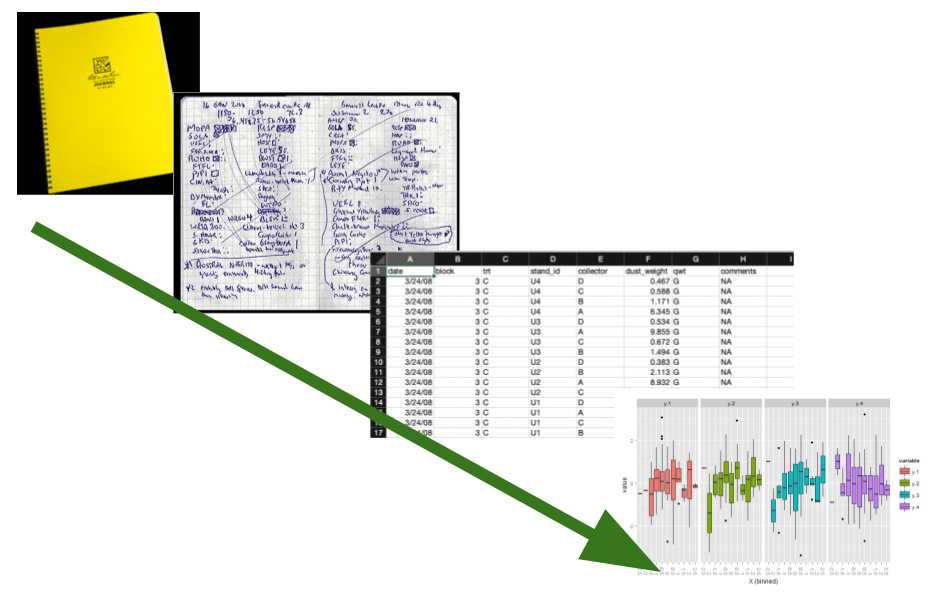
Collecting useful data
Research data are very diverse, but taking a thoughtful approach to collecting any data will make them more useful and easier to work with in the future. Below we consider several attributes of data you’ll encounter and work with in the real world:
- Intended use: How the data will be used
- Content and source: What the data are about and where they came from
- Data format: How data are represented in terms of structure, organization, and relationships
- File format: The physical format the data are stored in, such as a text file or JPEG image
Below, we provide data management recommendations organized around these attributes, with tabular data as our default example. Tabular data values fit into grid- or table-like structures with rows and columns representing observations and variables. This type of data, which includes delimited text files (like comma-separated value files, or CSVs), spreadsheets and similar, are the most common and recognizeable data type in the environmental sciences. There are plenty of data that aren’t exactly tabular, so the “Special cases” section is devoted to other types.
NoteIntroducing the “Dataset”
The four attributes of data highlighted above are the beginning of metadata, or data that describe other data. Metadata provide important context about the data we work with and are essential for making that data understandable and usable (we’ll devote more time to this later). Therefore, data and metadata should always travel together, and we have a special term for this pairing: a dataset. Datasets are fundamental units of information used in research, and important products of research activities, so we will refer to them often.
Intended use
The intended use, or how your data will be used, is something you should start envisioning early in the research process, probably around the same time you are considering hypotheses, experimental design, and analysis plans. Intended use of the data influences many of the decisions you’ll make during research, including data/metadata collection, formatting, quality assurance/control (QA/QC), and more. Its tough to give concrete advice here since there are many uses for any data, but here are a few questions you should ask:
- What is the research purpose of the data?
- What statistical analyses will you perform?
- Who will use the data, and will they be used for more than research?
- Will you publish the data? Where and when?
Keep in mind that new uses for data frequently arise during research, so you will probably end up revisiting these questions.
TipRecommendations
- Think about intended uses for the data early - ideally before you collect it.
- Consider how the data will be used beyond your research project.
Content and source
Many variables, about any number of phenomena, can be measured or observed. The content of the data refers to what the data you collect are about. So, what variables did you collect, and what real-world place, organism, thing, or process did you observe or measure them from? At the Jornada we are usually studying biotic or abiotic phenomena in our slice of the Chihuahuan Desert. Also pay attention to what is not in your data, e.g. what is excluded or missing, and any sources of bias. Remember that information about the content and limitations of your data will need to be in your metadata so it can provide context for a published dataset.
The source of the data refers to where the data came from and how they were acquired. So, were the data collected in the field by a primary observer? By an autonomous sensor system? Or did they come from another researcher? In modern research it is common to integrate data from multiple sources, and it pays to document those sources well. If you collect the data yourself you should describe how you did so with rich metadata, which will make your data useful for the long term. If you use previously-collected datasets, you’ll need to find, acquire, analyze, and interpret the data and then cite them. You’ll have an easier time with that if the dataset creators were diligent about their metadata.
TipRecommendations
For data content:
- Know what your data are about, including the system being studied, and the variables observed or measured.
- Be prepared to describe what the data are about in your metadata.
- Be aware of any requirements for, and limitations of, the data you collect (e.g. human subjects, endangered species, sampling bias).
For data source:
- Keep a detailed field or laboratory notebook to document your data collection activities.
- For autonomous data-collection systems (dataloggers, sensors, etc) keep extensive documentation, installation photos, and a log of changes and known issues.
- If you synthesize data from external sources or published studies, document the origin of all data you use.
Data format
There are at least two meanings wrapped up in the term data format. First, a data format describes the way data are structured, organized, and related.1 Tabular data formats, for example, resemble a grid where the columns and rows represent the variables and observations of the data, and there can be more than one way to arrange those. The second meaning of data format refers to the fact that the data values for any variable can be represented in more than one way. An identical date, for example, can be formatted as the text string “July 2, 1974” or as “1974-07-02.”
For tabular data, structuring the data you collect into the simplest possible table format is the best policy. First think about what variables you collect. Some will be categorical (treatment, plot number) and some are continuous (measured biomass, temperature). Then consider what an observation is. Is it a monthly measurement of a plant, or an hourly temperature value recorded by a sensor? Then, organize these values logically into clearly labeled columns and rows so that the data are understandable. If you’ve heard of “Tidy data”, this is a great mental model to use for organizing data in a table (Wickham 2014 — more details below). In tidy tables, the columns are always variables and the rows represent observations (more details below). If you want to make sure the tabular data you collect follow fairly strict rules, consider using a relational database. Databases are not as simple as text files, but they do offer significant advantages for consistency and integrity of data.
When you format the actual data values within the table, use the most understandable and granular format you can. For example, if you have a nested experimental design with blocks, plots and individuals, separate the values for these variables into different columns and make sure they are consistent. For date and time values, we recommend using the ISO standard (YYYY-MM-DD) rather than the traditional month-day-year (mm/dd/yy) format. If you use a database, you can ensure standard formats are used by applying rules in the database (constraints).
In this example table you can see several data no-no’s.
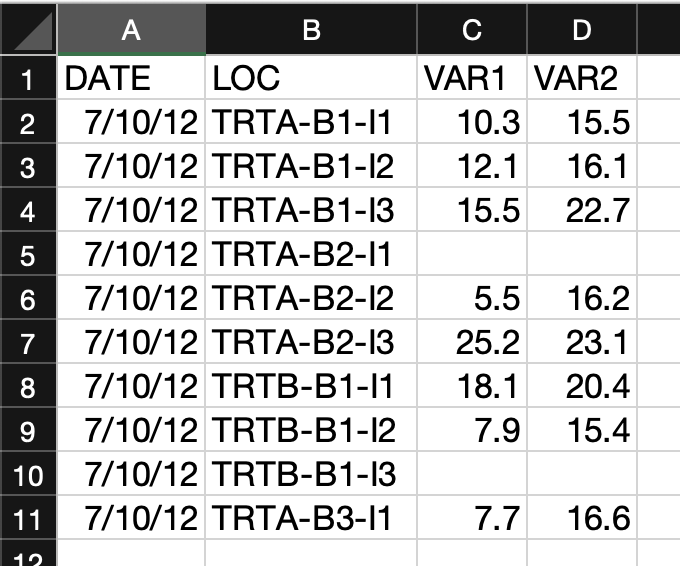
- Several categorical variables have been joined into one in the “LOC” column.
- The variable names don’t give you a hint of what they are.
- The “DATE” column would be easy to misinterpret.
- There is no missing value indicator. For blank observations, was the individual missing or did the observer make a mistake?
In this example most of those issues have been corrected.
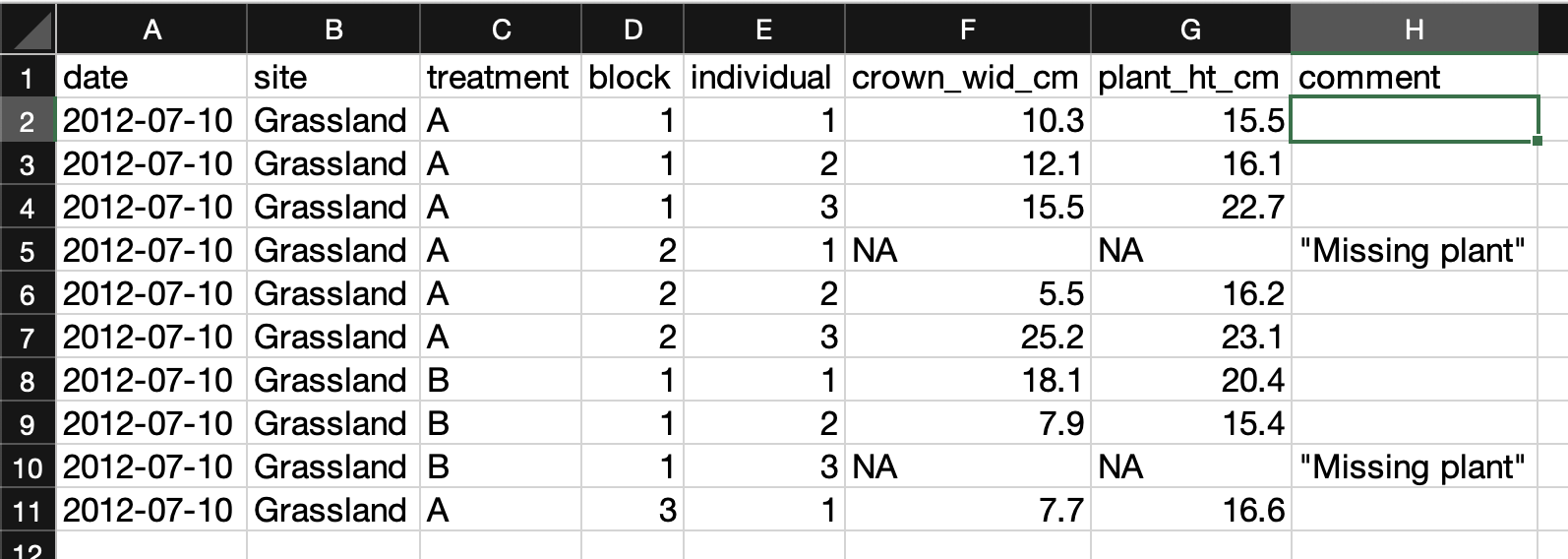
- The variable columns are distinct and have granular values with clear column labeles.
- The date column follows the ISO standard (YYYY-MM-DD).
- “NA” values are used for missing data, and there is a comment column indicating what they mean.
Relational databases are collections of data tables that follow specific rules and have relationships connecting them to each other. In each table, rows hold a specific kind of data record refering to entities like observations, study sites, or organisms, and columns hold the variables (or “attributes”) for the records. Records in different tables are related to each other via values in shared columns (“foreign keys”). The tables, columns, and relationships are defined in a database schema. Databases are a consistent and space-efficient way to store multidimensional data. Here’s a diagram of a relational database schema with three tables:
(Note this only works in new versions of Mermaid - Quarto is a little behind and will be up to date in 1.9. Preview here)
The plants table holds records of measured plant dimensions and related variables, which are connected to a specific sampling event. The sampling_event table holds information about those events, including date, observer, and the plot sampled. The plots table is connected to sampling_event by the plot_id field and stores information about the name, location and treatment of the research plots.
CautionMore about Tidy data
In the Tidy data paper (Wickham 2014), the claim is that “80% of data analysis is spent on the process of cleaning and preparing the data.” Adhering to a clear, easy-to-understand data format can help lower this burden and make data easier to clean, filter, and analyze. The tidy data model, or “long” format, aims to do this by following three rules:
- Each column holds one variable.
- Each row represents observation.
- Each cell holds a single value.
The resulting tables look like so:

This is in contrast to “wide,” or “untidy,” format, in which variables and observations may be organized in either rows or columns. The same data in wide/untidy format could look like either of these tables:
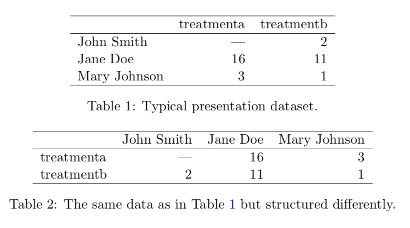
Keep in mind that wide/untidy format isn’t always bad. Wide tables tend to take up less space on disk, and in addition, they can be called for in many standard statistical analyses.
Bottom line: Tidy data is a great default format with several advantages, but be ready to use wide/untidy formats when necessary too.
TipRecommendations
- Use the simplest possible data structure.
- Organize data by observational unit during collection.
- Maximize the information for each observation.
File formats
The file format of your data refers to the physical file type that your data are stored in on a disk or other storage medium. File formats usually have a specification (or set or rules), a name, and a file extension. Some examples would be a delimited text file (file extension .txt, or others), a Microsoft Excel file (file extension .xls or .xlsx), or a JPEG image (file extension .jpg or .jpeg). File formats usually depend on the data content or source, and are sometimes specific to particular data uses or software programs. Whenever possible, try to choose file formats that are (a) simple to use and understand, and (b) accessible and familiar to your community or collaborators. For tabular data we usually recommend delimited text files, like the trusty CSV, whenever possible, but there are other choices to consider, and pros and cons for each, below.
Delimited text files are a great format for using, archiving, and sharing your data. Rows of data values are stored as lines in a text files with a designated character serving as the delimiter between columns of data. They are human-readable, simple to understand, fairly space-efficient, and easy to use with almost any tool in your data workflow (R, Python, Excel, GIS software, etc.). They may have a .txt, .csv, .tsv, or other file extension depending on the delimiter and convention.
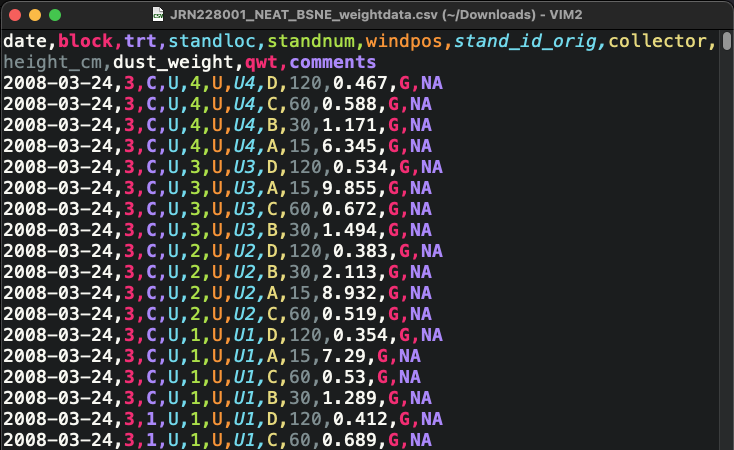
Microsoft Excel is a powerful spreadsheet program with a long history of use in research. Excel spreadsheets live in the .xlsx file format, though there are many other non-Microsoft formats Excel can read and write, including CSV and ther delimited text files. Also note that Microsoft Excel is not the only spreadsheet game in town. Google Sheets and LibreOffice Calc are both full-featured and can interoperate with Excel file formats very well.
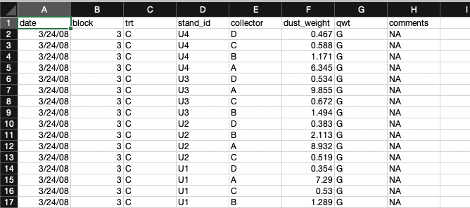
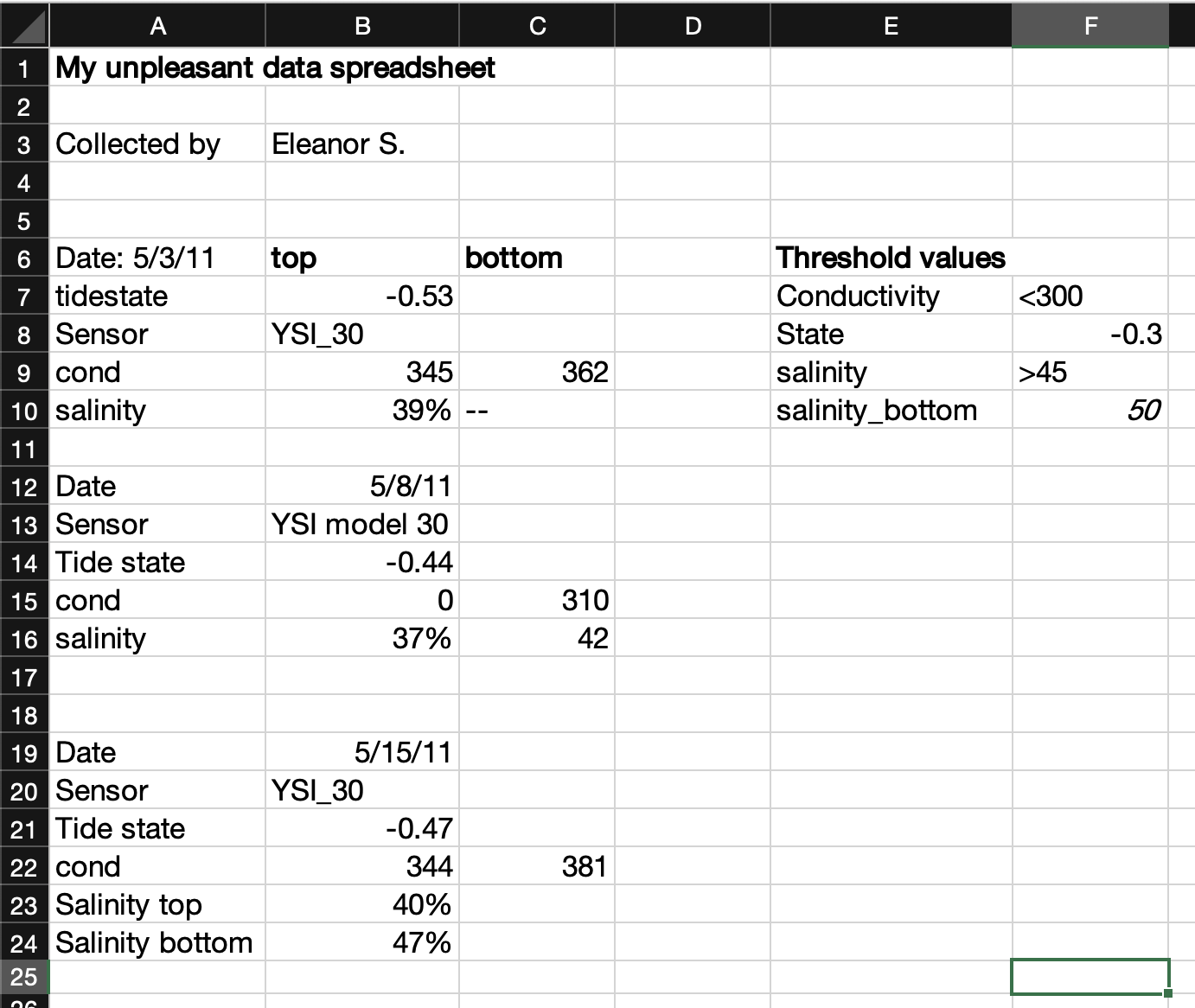
Unfortunately, spreadsheets sometimes make the wrong assumption about the data you enter, and they are prone to being used in non-standard ways. That makes spreadsheet files a little less friendly as an archive and distribution format for research data. See the example below.
We discussed how relational databases structure data in the “Data format” section above. Databases are often used for very large data stores that are accessed by enterprise-level applications over a network, so they can be much more complicated than file-based data formats. But, there is a range to this complexity and there are some very friendly file-based databases that you can use easily on your local computer, share over email, or publish to a repository.
- SQLite is a single-file database.

- DuckDB is a single file columnar database optimized for big data analysis.

Keep in mind that you’ll probably need to learn some new skills to use the data in a database, particularly if they are large or have a complex schema (many linked tables). The Structured Query Language, or SQL, is the standard programming language for working with data in databases. Basic SQL is not too hard to learn, and it is useful for more than just database queries because it has been integrated into many data science tools like the R “tidyverse”, various Python libraries, and others.
Tools and resources
- DB Browser for SQLite is a good, cross-platform database browser for SQLite databases that is easy to use.
As we move towards creating and using high-volume research data, and employing cloud storage and computing services in research, there are some more advanced file formats to consider.
- Parquet files and other columnar formats
- Some databases
There are many other possible tabular data file formats. Some are good for quick, space-efficient storage, but not ideal for long-term preservation. Keep in mind that many of these formats are not easily human-readable without specialized sofware, so they may be difficult for novices to use. They may also be harder to describe with metadata, especially when publishing the daaset. Here are a few possible examples:
- R data binaries: R provides two file formats for storing data. RDS files (
.RDS) store a single R object, and RData files (.RDataor.rda) store multiple objects. - Python data binaries: There are many, including Numpy single and multi-array archives (
.npyand.npz), Pytables, pickle, and more - NetCDF and HDF5
- JSON and XML
- Apache Feather
TipRecommendations
- Use open, community-standard file formats instead of proprietary ones whenever possible.
- Try to use the simplest file format possible for your data.
- For tabular data, the delimited text file, or CSV, is a sensible default.
Special case data
Above, we’ve used tabular data as the default example, but like people, all data are special in their own way and they don’t always fit into a traditional tabular mold. Modern research datasets are becoming larger and more complex, multifaceted and distributed, meaning that we more often need to move beyond the simple data table paradigm. Examples include imagery, geospatial data, high-frequency sensor data, genomic data, models, and more. Some of these can still be represented in grid or table form, but because of high volume and complexity it helps to handle them differently. There is a detailed Data Package Design for Special Cases guide from LTER Network IMs and EDI with excellent guidance for special cases like these (Gries et al. 2021).
Images captured from cameras or similar imaging sensors. Individual images are usually represented as a rectangular grid of pixels with color, reflectance, or similar data values for each pixel, and there are often multiple bands (layers) in an image. Imagery data is very diverse and widely used in research.
| Intended use |
|
| Content |
|
| Source (or acquisition method) |
|
| Data format |
|
| File format |
|
Data collected from environmental sensors
| Intended use |
|
| Content |
|
| Source (or acquisition method) |
|
| Data format |
|
| File format |
|
Geospatial data types are “georeferenced,” meaning some kind of location information is included with each observation.
| Intended use |
|
| Content |
|
| Source (or acquisition method) |
|
| Data format |
|
| File format |
|
Molecular data types contain information about DNA, RNA, proteins, or other biological polymers in organisms or the environment. They can contain, for example, the sequence of nucleotides in DNA extracted from organisms or environmental materials like soils. These data may be complete genomes or other “omes” (transcriptome, metabolome, etc.), meaning the full sequence of a particular molecule, gene, or organism, and sometimes only specific markers within longer sequences are identified and included in the data (genotyping or barcoding approaches). In most cases, extensive metadata annotations and information about field/laboratory procedures and bioinformatics pipelines are needed to make these data interpretable.
TABLE TBD!
| Intended use |
|
| Content |
|
| Source (or acquisition method) |
|
| Data format |
|
| File format |
|
Cleaning and QA/QC
The Jornada IM team has a significant amount of experience and a variety of tools to draw on for quality assurance and quality control (QA/QC) of long-term Jornada datasets. For data managed by individual researchers, the Jornada IM team leaves most data QA/QC up to the research group or individual, but we are happy to advise when asked. For a simple overview and some resources useful for QA/QC of tabular data, see EDI’s recommendations.
Describing your data (Metadata!)
As you collect and work with your data, there is a large amount of contextual information about the data that is accumulating. This contextual information is called metadata, and you don’t want to lose track of it because it can be critically important for understanding and using the data later. Metadata are data about the data, and as a general rule, they should describe
- Who collected the data
- What was observed or measured
- When the data were collected
- Where the data were collected
- How the data were collected (methods, instruments, etc.)
- Sometimes, stating why the data were collected can help future users understand data context and evaluate fitness for use.
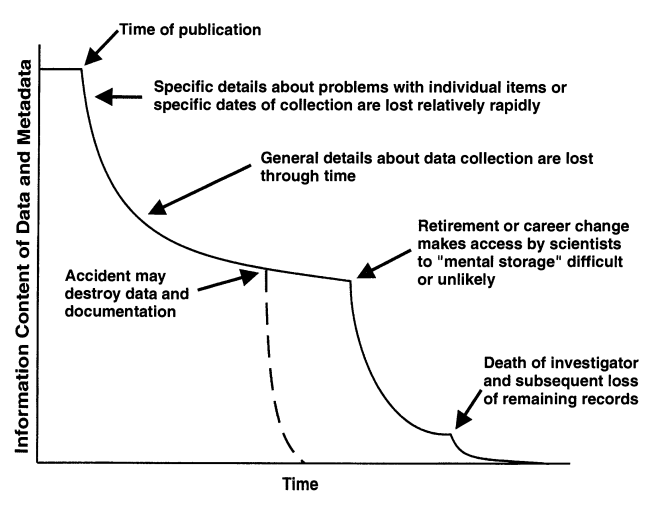
Preserving these metadata along with your actual data (measurements, observations, etc.) makes them more usable, and helps prevent the loss of information about data over time, as illustrated in Figure 2. Metadata are also essential to the reproducibility of research results, so when it comes time to publish the data, you’ll have to provide adequate metadata.
Creating and managing metadata
Assembling and preserving metadata is important and should be an integral part of most research activities, including day-to-day data work and project management practices. Below are a few suggestions on how to start.
- Keep a detailed project log and populate it with useful metadata, such as:
- how new data are collected,
- for ancillary data (not directly collected by you), documentation of the original data source,
- how the data are cleaned, quality assured, and prepared for analysis,
- data analysis steps and methods used to create figures, statistics, and derived data products,
- who is doing what.
- Think about what datasets are most valuable and how they should be published.
- You can’t publish every single data file you have, so decide what will be most interesting and useful for other researchers and your future self.
- After you prioritize some research products for publication, consider what people will need to know to use them effectively.
- This gives you a target for collecting appropriate metadata for your published dataset.
- Start creating structured metadata files and keep them with your data.
- Try to be systematic and complete about describing your data with metadata. A metadata template, such as one of the Jornada templates, helps with this.
- Organize your research products in clearly-labeled project directories where data and metadata live together.
- Eventually, you will probably need to create a standard metadata file, such as EML, to publish your data. Applications for editing metadata, such as ezEML from the Environmental Data Initiative (EDI) repository, are a huge help with this task.
As always, discussing your project with a data manager or data curator and asking for advice about any of these activities is a smart move. At the Jornada, the Information Management team is happy to help, or you can reach out to curators at our partner repository Environmental Data Initiative.2 Other repositories and academic libraries often have professional data curators on staff who are well-trained and can advise researchers on community metadata standards and best practices for data publishing.3
TipRecommendations
- You need data AND METADATA to make a usable dataset and get it published.
- Make sure to plan for and start creating metadata early in your research.
- Keep your research files well-organized, documented, and keep metadata and data together.
- Ask your friendly neighborhood data manager for help anytime.
Storage and backup
Store your data securely and have a reliable backup system for them.
References
Gries, Corinna, Stace Beaulieu, Renee F Brown, Sarah Elmendorf, Hap Garritt, Gastil Gastil-Buhl, Hsun-Yi Hsieh, et al. 2021. “Data Package Design for Special Cases.” Environmental Data Initiative. https://doi.org/10.6073/PASTA/9D4C803578C3FBCB45FC23F13124D052.
Michener, William K., James W. Brunt, John J. Helly, Thomas B. Kirchner, and Susan G. Stafford. 1997. “Nongeospatial Metadata for the Ecological Sciences.” Ecological Applications 7 (1): 330–42. https://doi.org/10.1890/1051-0761(1997)007[0330:NMFTES]2.0.CO;2.
Wickham, Hadley. 2014. “Tidy Data.” Journal of Statistical Software 59 (September): 1–23. https://doi.org/10.18637/jss.v059.i10.
Footnotes
The concepts of data formats and data structuring can become fairly complicated and are related to the disciplines of database design and data modeling. For example, when designing a database one must decide what the entities (real-world concepts), tables (relations), attributes (columns), and foreign-key relationships (links between tables/columns) are. We won’t go into this much depth here, but it can sometimes be useful to have a detailed conceptual picture of how your research data fit together.↩︎
Reach out to the Jornada IM team at jornada.data@nmsu.edu, or to the EDI support channel at support@edirepository.org. Here is a list of Information Managers at all LTER sites.↩︎
The Data Curation Network is a professional membership organization for data curators.↩︎